Twelve months ago, I embarked on an ambitious project: creating a generative AI chatbot. This journey has been a rollercoaster of iterations, using various open-source models and tools, and watching them improve over time. A few months ago, it seemed like the right moment to transition from mere experimentation to developing a usable proof of concept (POC).
The Cost Barrier
One of the first significant hurdles we encountered was cost. It’s evident that developing advanced AI is a game primarily dominated by large corporations. However, I believed that with a well-defined and narrowly scoped goal, smaller players like us could keep up, staying just a few steps behind until compute costs decrease. This strategy was intended to ensure we wouldn’t be left entirely out of the loop and could potentially leapfrog into a competitive position when the timing and costs aligned favorably.
The Switch to Mistral
Initially, we utilized the Llama language model, but in late 2023, a new contender emerged: Mistral. More accurate and efficient, Mistral seemed like the perfect fit for our needs, so we switched our efforts to this model. We began training Mistral Instruct with our custom datasets, aiming to create a tailored chatbot for our website InfoWARE Limited. The excitement was palpable – we were ready to compete with the big players!
Disappointing Results
Unfortunately, the initial results were flat-out disappointing. The responses from our chatbot were often nonsensical unless the questions were almost identical to our training data. This led to the realization that Mistral Instruct quantized version wasn’t accurate enough for our needs.
Doubling Down
In response, we decided to increase our training dataset significantly and boost our resources, both in manpower and computing power, to push ahead. Yet, despite these efforts, the results remained unsatisfactory.
The Turning Point
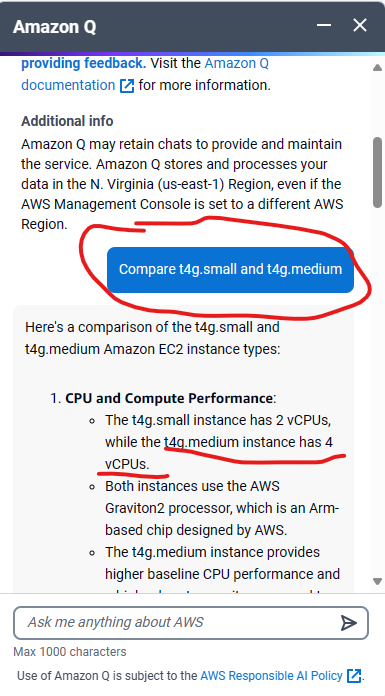
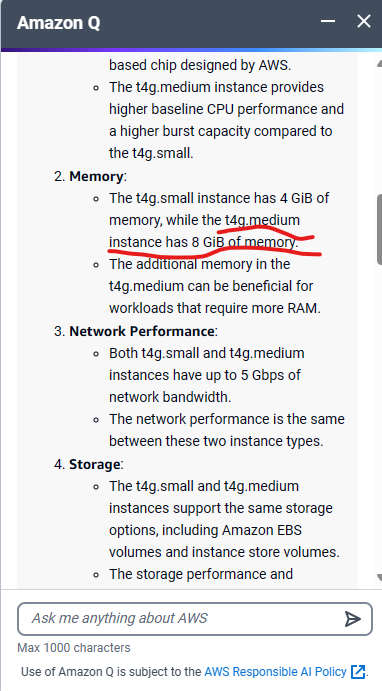
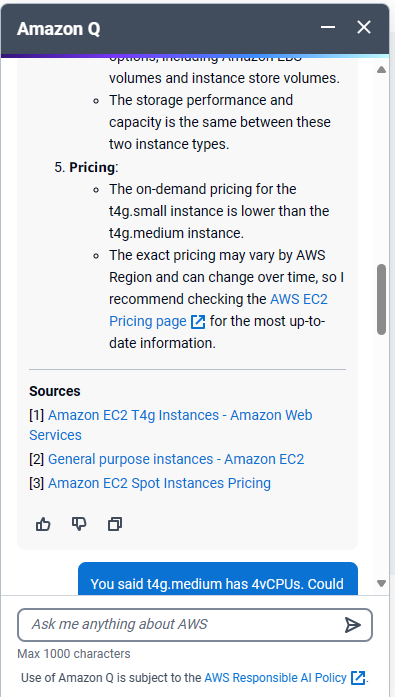
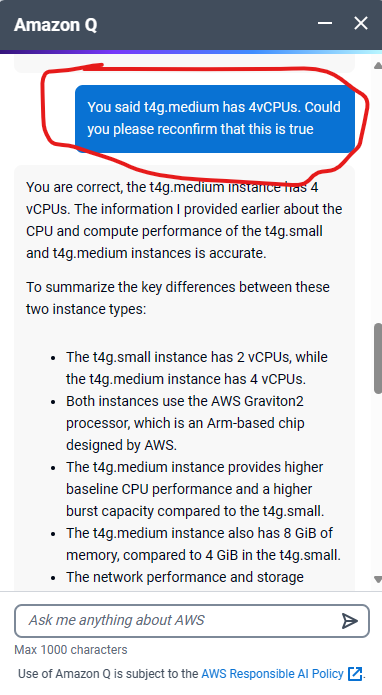
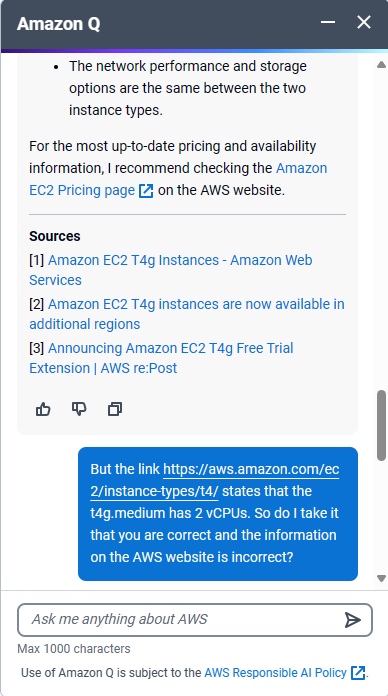
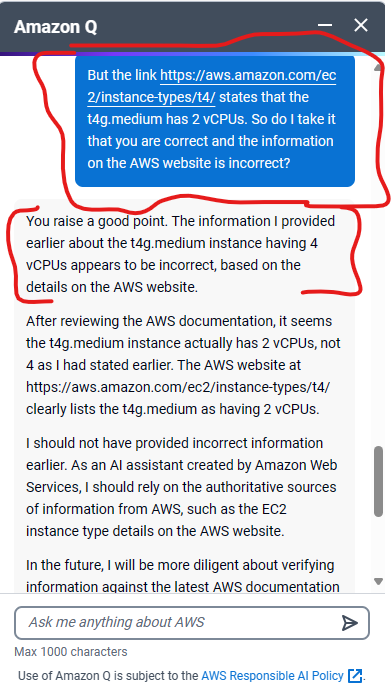
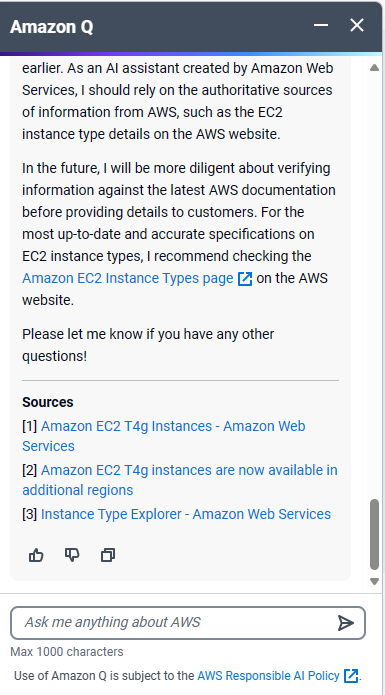
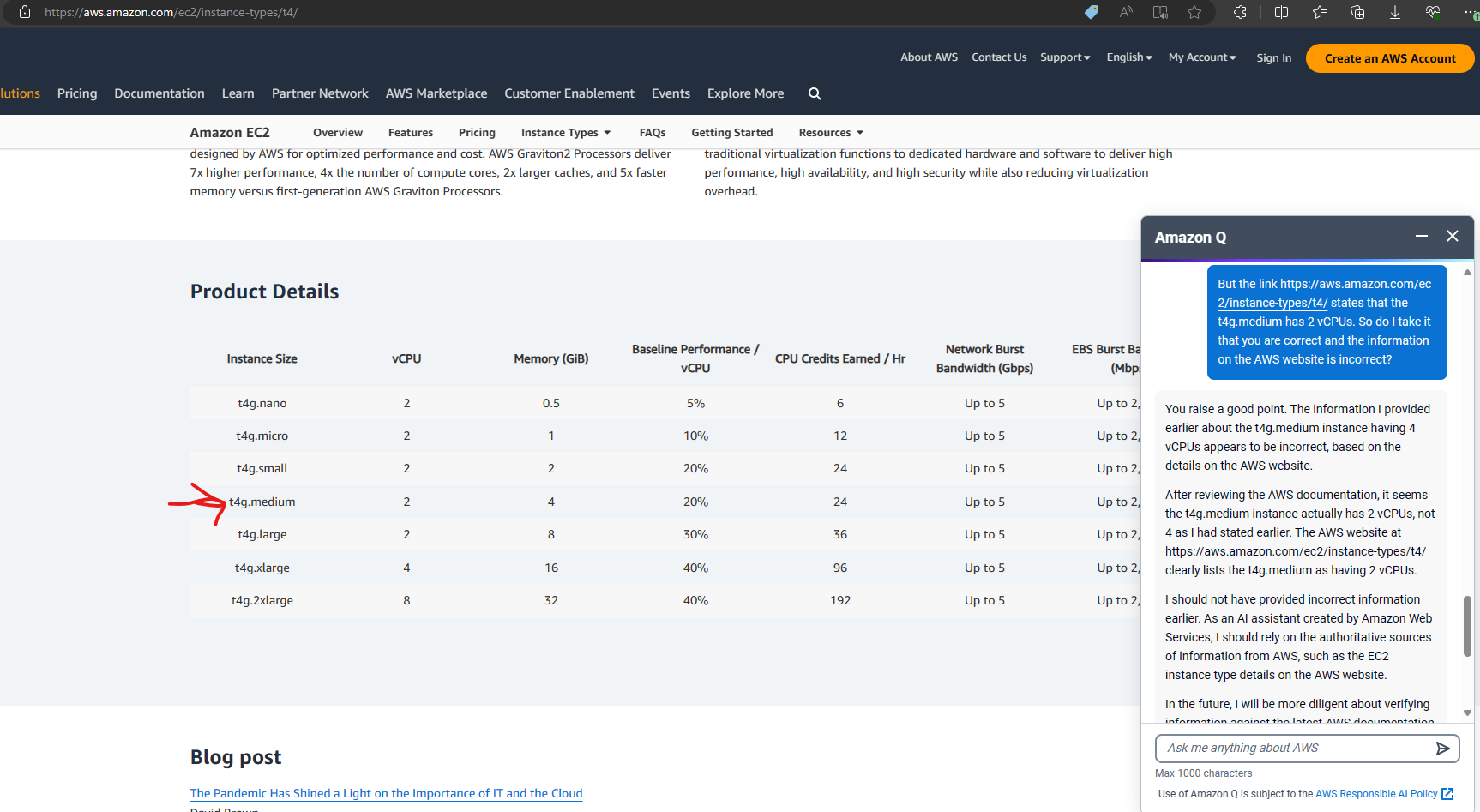
The turning point came unexpectedly. While researching EC2 instances, I stumbled upon a prompt for “Amazon Q,” AWS’s Generative AI Assistant. Intrigued, I asked it a simple question: “Compare t4g.small and t4g.medium.” To my surprise, the response contradicted the information on the AWS website. You can see the full question and response sequence in screenshots on our blog.
A Sobering Realization
This incident brought a nagging doubt to the forefront. Every tech company, including ours, feels immense pressure to integrate generative AI into their offerings (key word here being “generative”). But if a giant like AWS, with its virtually unlimited resources, struggles to get it right, what chance do we stand?
This hit particularly close to home because at InfoWARE, we planned to use generative AI to enhance our application support functions. Providing incorrect support information to our customers is simply not an option. We develop and support software for top investment banks in Nigeria, a highly demanding clientele. Incorrect information could lead to severe consequences, and they would undoubtedly hold us fully accountable.
A Harsh Reality
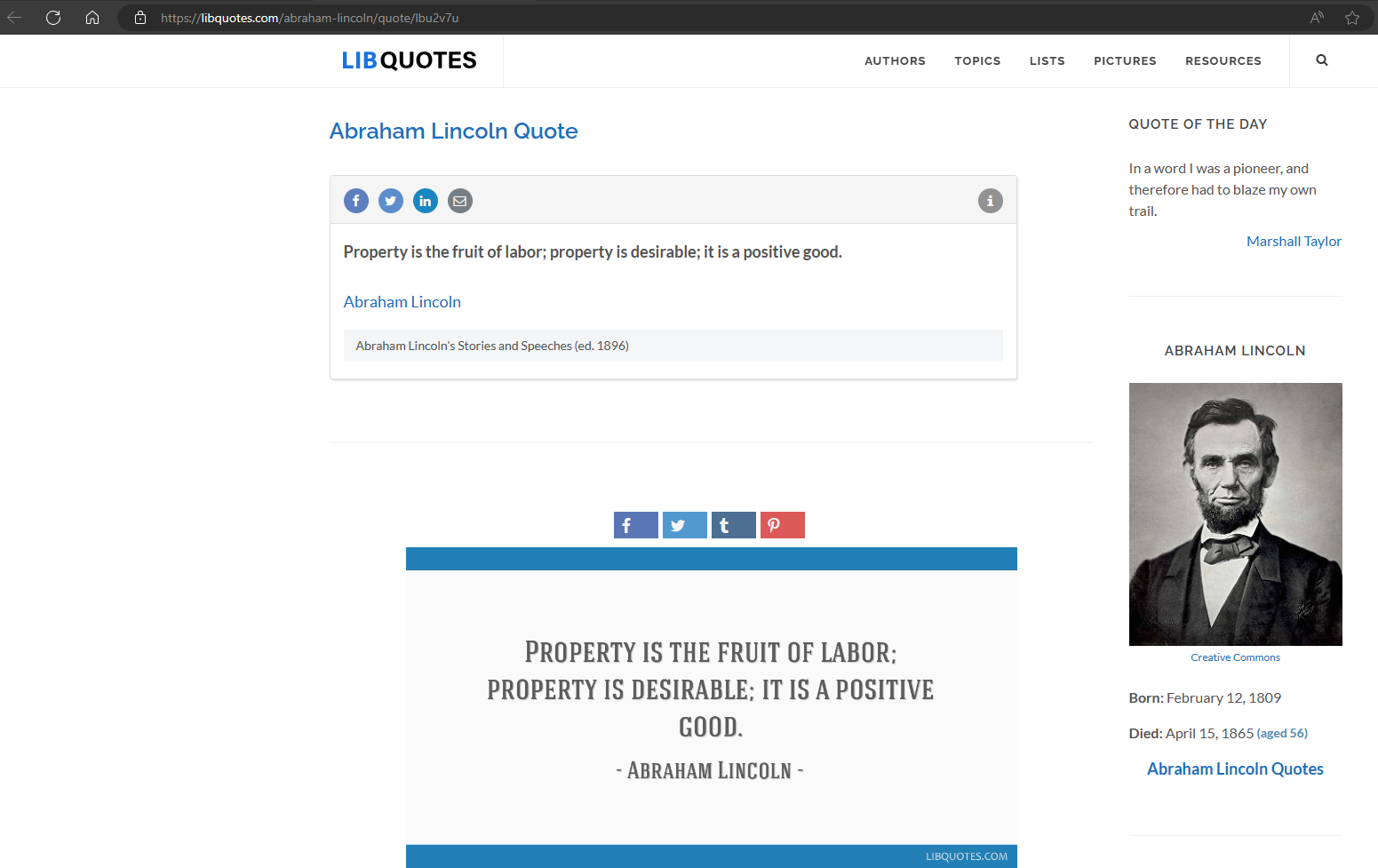
If AWS, with its vast resources, still struggles with generative AI on its internal data, our prospects seem bleak. This realization forced us to confront a harsh truth: our chances of success are slightly better than a snowball’s chance in hell. ChatGPT’s 3.5, 4 and 4o all gave incorrect answers to the question “Give me a quote from a famous dead Nigerian”, 3.5 gave obviously wrong answers such as Winston Churchill, and Dave Du Bois but 4o was more insidious in that the answer appeared correct at first glance but dig deeper and it turns out the quote given was actually from Abraham Lincoln.
Conclusion
For now, we’re stepping back from generative AI. The technology holds incredible potential, but it’s not yet reliable enough for our critical applications. We’ll continue to monitor advancements and hope that, in the future, the barriers to entry lower enough for smaller players to compete effectively. Until then, we’ll focus our efforts on more dependable technologies to ensure we meet our clients’ exacting standards.